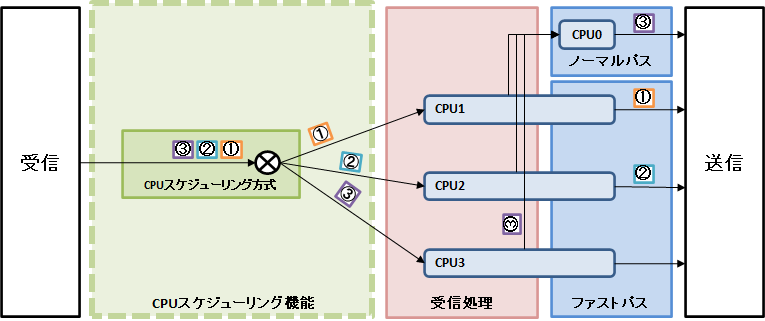
図1. パケット転送処理の流れ
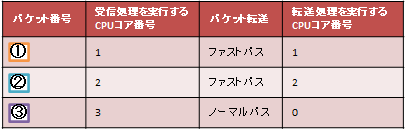
表1. 受信パケット一覧
$Date: 2024/10/10 17:26:48 $
vRX シリーズはマルチコアCPUに対応しています。CPUスケジューリング(パケット振り分け)機能は、ルーターがパケットを受信したときに、受信パケットの転送処理をどのCPUコアで実行するかを決定するための機能です。本機能により、以下のような受信パケットの転送処理を実行するCPUコアの割り当てを行うことができます。
CPUスケジューリング方式は、受信パケットの転送処理をどのCPUコアで実行するかを決定するための機能で、方式ごとに定められた観点から、パケットの転送処理をどのCPUコアで実行するかが決定されます。CPUスケジューリング方式には、以下の方式があります。
ノーマルパスの処理対象となるパケットは、本機能によって決定されたCPUコアでは受信処理のみが実行され、転送処理は常にCPU0で実行されます。
図1. パケット転送処理の流れ
表1. 受信パケット一覧
受信パケットはCPUスケジューリング方式に従って決定されたCPUコアで転送処理が実行されます。ノーマルパス対象パケットは本機能により決定されたCPUコアでは受信処理のみが実行され、転送処理は常にCPU0で実行されます。
vRXシリーズの以下の機種とリビジョンで、CPUスケジューリング(パケット振り分け)機能をサポートしています。
| 機種 | リビジョン |
|---|---|
| vRX Amazon EC2版 | すべてのリビジョン |
| vRX VMware ESXi版 |
ルーターは system packet-scheduling コマンドで設定したCPUスケジューリング方式ごとに定められた観点から受信パケットの転送処理をどのCPUコアで実行するかを決定します。CPUスケジューリング方式は以下の中から選択することができます。
ロードバランス方式では受信パケットの振り分けをソフトウェアで行うため、NIC側で受信パケットの振り分けを行う他の方式の方が、スケーラビリティに優れています。他の方式を優先的に使用することを推奨します。
ハッシュ方式では、受信パケットのヘッダ情報から算出されたハッシュ値を基にしてパケットの転送処理をどのCPUコアで実行するかが決定されます。同じフローのパケットであれば、常に同じCPUコアで転送処理が行われます。
IPsecではESPシーケンス番号の順序通りにESPパケットが送信されないことがあるため、対向側ルーターの受信処理でESPシーケンスエラーが発生し、ESPパケットが破棄される可能性があります。ESPシーケンスエラーは、対向側ルーターの ipsec sa policy コマンドで anti-replay-check を off にして、ESPシーケンス番号のチェックを行わないようにすることで回避できます。
ハッシュ値の算出に使用されるヘッダ情報は以下のとおりです。
| ヘッダー情報 | vRX Amazon EC2版 | vRX VMware ESXi版 | |
|---|---|---|---|
| プロトコル | パラメーター | ||
| IPv4/IPv6 | 送信元アドレス | ○ | ○ |
| IPv4/IPv6 | 送信先アドレス | ○ | ○ |
| IPv4/IPv6 | プロトコル番号 | ○ | × |
| TCP over IPv4/IPv6 | 送信元ポート番号 | ○ | ○ |
| TCP over IPv4/IPv6 | 送信先ポート番号 | ○ | ○ |
| UDP over IPv4/IPv6 | 送信元ポート番号 | ○ | ○ ※1 |
| UDP over IPv4/IPv6 | 送信先ポート番号 | ○ | ○ ※1 |
| ESP over IPv4 | SPI | × | ○ ※1 |
IPv4/IPv6ヘッダを持たない受信パケットの転送処理はCPU0で実行されます。
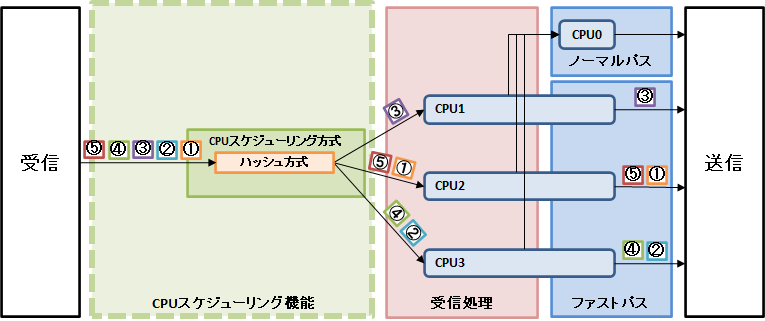
図2. ハッシュ方式によるパケット転送処理の流れ
表2. 受信パケット一覧
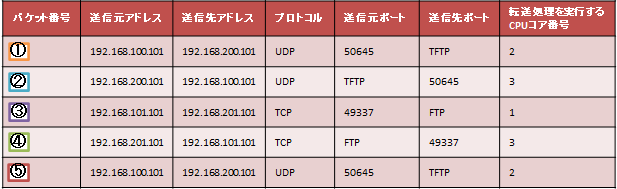
パケット①〜⑤の転送処理は、パケットのヘッダ情報から算出されたハッシュ値を基にして決定されたCPUコアで実行されます。パケット①とパケット⑤はヘッダ情報が同じであるため、転送処理を実行するCPUコアも同じになります。
ロードバランス方式では、各CPUコアの負荷が均等になるようにパケットの転送処理をどのCPUコアで実行するかが決定されます。転送処理を実行するCPUコアがパケット単位で変化するため、同じフローのパケットであっても、毎回同じCPUコアになるとは限りません。
受信パケットのヘッダ情報を意識しなくとも、パケットの転送処理をすべてのCPUコアで実行することができるようになるため、ハッシュ方式ではCPU負荷に偏りが生じてしまう場合などに、全体のCPU負荷を分散させることができます。
同じフローのパケットの転送処理をすべてのCPUコアで実行するため、パケットの順番が入れ替わる可能性があります。パケットの順番が入れ替わるとUDPを用いるアプリケーションで問題が発生する可能性があります。なお、TCPではパケットの順番が入れ替わっても通常は問題は発生しません。
IPsecではESPシーケンス番号の順序通りにESPパケットが送受信されないことがあるため、両側のルーターでESPシーケンスエラーが発生し、ESPパケットが破棄される可能性があります。ESPシーケンスエラーは、両側のルーターの ipsec sa policy コマンドで anti-replay-check を off にして、ESPシーケンス番号のチェックを行わないようにすることで回避できます。
ロードバランス方式を指定した場合には、トラフィックが存在しない状況でも新たなパケットの到着確認にコア1以降を使用します。パケットの到着を確認できなかった場合に使用したCPU時間は、show environment コマンド、および、show environment detail コマンドで表示されるCPU使用率に計上されませんのでご注意ください。
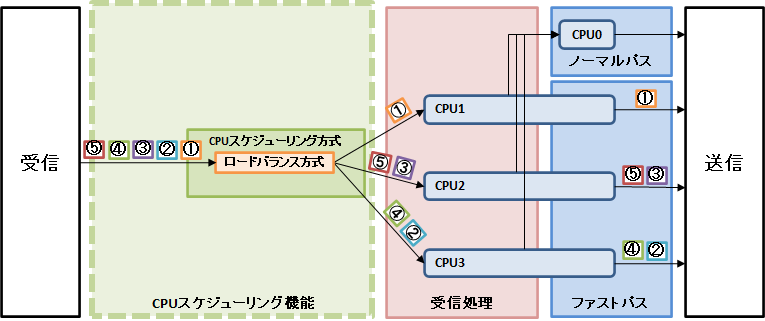
図3. ロードバランス方式によるパケット転送処理の流れ
表3. 受信パケット一覧
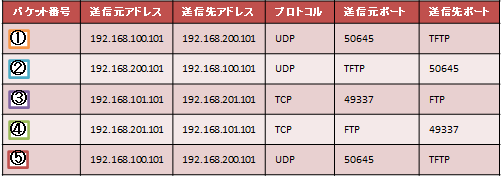
パケット①〜⑤の転送処理は、各CPUコアの負荷が均等になるように決定されたCPUコアで実行されます。ここではパケット①の転送処理はCPU1で実行されていますが、パケット①と同じヘッダ情報を持つパケット⑤の転送処理はCPU2で実行されています。
LANインターフェース方式では、パケットを受信したLANインターフェースによってパケットの転送処理をどのCPUコアで実行するかが決定されます。
受信パケットのヘッダ情報を意識しなくとも、パケットの転送処理を意図したCPUコアで実行することができますが、ネットワーク構成によってはCPU負荷に偏りが生じる可能性があります。
IPsecではESPシーケンス番号の順序通りにESPパケットが送信されないことがあるため、対向側ルーターの受信処理でESPシーケンスエラーが発生し、ESPパケットが破棄される可能性があります。ESPシーケンスエラーは、対向側ルーターの ipsec sa policy コマンドで anti-replay-check を off にして、ESPシーケンス番号のチェックを行わないようにすることで回避できます。
受信LANインターフェースごとの転送処理を実行するCPUコアは以下のようになっています。
| 受信LANインターフェース | CPUコア |
|---|---|
| LAN1 | CPU1 |
| LAN2 | CPU2 |
| LAN3 | CPU3 |
| LAN4 | CPU1 |
ただし、CPUコア数が2、LANインターフェース数が3のときには、以下のようになります。
| 受信LANインターフェース | CPUコア |
|---|---|
| LAN1 | CPU1 |
| LAN2 | CPU1 |
| LAN3 | CPU1 |
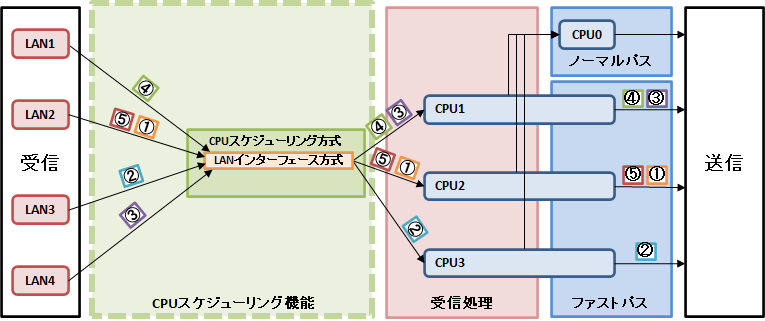
図4. LANインターフェース方式によるパケット転送処理の流れ
表4. 受信パケット一覧
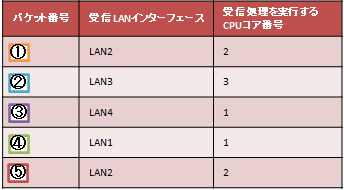
パケット①〜⑤の転送処理は、それぞれのパケットを受信したLANインターフェースに対応したCPUコアで実行されます。
固定方式では、すべてのパケットの転送処理がCPU1で実行されます。
IPsecではESPシーケンス番号の順序通りにESPパケットが送信されないことがあるため、対向側ルーターの受信処理でESPシーケンスエラーが発生し、ESPパケットが破棄される可能性があります。ESPシーケンスエラーは、対向側ルーターの ipsec sa policy コマンドで anti-replay-check を off にして、ESPシーケンス番号のチェックを行わないようにすることで回避できます。
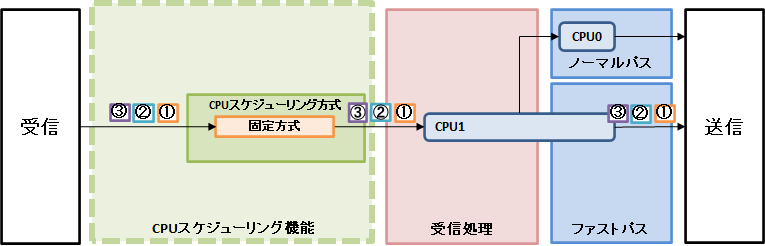
図5. 固定方式によるパケット転送処理の流れ
表5. 受信パケット一覧
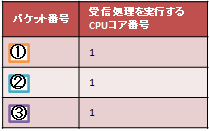
パケット①〜③の転送処理は、すべてCPU1で実行されます。