$Date: 2025/08/18 15:18:13 $
ヤマハルーターのうちいくつかの機種では、パケット転送を高速に行うためにファストパスと呼ばれる技術が利用されています。ファストパスでは、パケット転送を高速に行なえますが、その代わりに一部の機能に制約があります。この文書ではファストパスの仕様について解説します。
ファストパスはハードウェアによる実装とソフトウェアによる実装があり、利用しているCPUによってそれぞれ異なります。ファストパスを実装しているヤマハルーターでは以下のようなCPUを利用しています。
| 実装方式 | 機種 | CPU | ファストパス | |
|---|---|---|---|---|
| IPv4 | IPv6 | |||
| ハードウェア | RTX2000 | Intel IXP1200 | すべてのリビジョン | - |
| RTX1500 | ADI AD6846 | すべてのリビジョン | ||
| ソフトウェア (マルチコア) | vRXシリーズ | x86_64 | ||
| RTX5000 | PowerPC | |||
| RTX3510 | ARM | |||
| RTX3500 | PowerPC | |||
| RTX1300 | ARM | |||
| ソフトウェア (シングルコア) | RTX1220 | PowerPC | ||
| RTX1210 | PowerPC | |||
| RTX1200 | MIPS | |||
| RTX1100 | MIPS | Rev.8.03.37以降 | ||
| RTX1000 | MIPS | Rev.7.01系 | - | |
| RTX840 | ARM | すべてのリビジョン | すべてのリビジョン | |
| RTX830 | ARM | |||
| RTX810 | ARM | |||
| RT107e | MIPS | Rev.8.03.42以降 | ||
| FWX120 | ARM | すべてのリビジョン | ||
| SRT100 | MIPS | |||
| NVR700W | ARM | |||
| NVR510 | ARM | |||
| NVR500 | ARM | |||
| RT58i | XScale | |||
| RT57i | MIPS | - | ||
| RTV700 | MIPS | - | ||
ファストパスとは、パケット転送を高速に処理するための仕組みです。ファストパスを使わずにパケットを転送する処理は、ノーマルパス、あるいはスローパスと呼んでいますが、どちらも同じ意味です。
ファストパスでは、パケットを高速に処理するために特別なテーブルを持っています。
ソフトウェア実装の機種、およびRTX1500ではすべての場合で、RTX2000では後述する独自経路テーブルで扱えない場合には、ルーターが処理するパケットを種類別に分類して、フローとして扱います。フローとして分類する際に利用する情報は以下の通りです。
フローの先頭のパケットはノーマルパスで処理しますが、その際にフローをどのように処理するかをフローテーブルに記録しておきます。この時フローテーブルに記録するのは、パケットをフィルタで落すかどうか、NAT/IPマスカレード変換したならばどのように書き換えるか、パケットを送信するポートとその時のL2ヘッダ、などがあります。
フローの後続のパケットは、フローテーブルに記録されている情報を参照してファストパスで処理を行ないます。ノーマルパスで必要な、経路テーブルの参照、フィルタの適用、NAT/IPマスカレードテーブルの参照、L2ヘッダの構築などがフローテーブル一つですべて処理できるためにノーマルパスに比べて圧倒的に高速な処理が可能になっています。
フローテーブルのサイズは有限で、別表のようになっています。1つのセッションでは方向別に2つのフローを必要とするので、同時に管理できるセッションはそれぞれ約半分となります。これ以上のセッションについては、ノーマルパスで処理されることになります。
RTX2000では、ファストパス独自の経路テーブルを持っています。以下の条件にすべて合致する場合には、独自の経路テーブルに従ってパケットをファストパス処理することができます。
複数のゲートウェイを持つ経路とは、以下の経路のことです。
RTX2000のRev.7.00系ファームウェアでは複数のゲートウェイを持つ経路は利用できません。複数のgateway句を持つip routeコマンドはエラーとなりますし、OSPFのイコールコストマルチパス経路でもそのうちの1つだけが経路テーブルに登録されます。Rev.7.01系のファームウェアでは、複数のゲートウェイを持つ経路が利用できるようになりますが、複数のゲートウェイを持つ経路がある場合には、フローテーブルを用いた処理となります。
これらの条件に合致しない場合には、前述のフローテーブルを用いた処理を行ないます。また、RTX2000以外の機種では、ファストパス独自の経路テーブルを持っていませんので、ファストパスは常にフローテーブルを用いる処理になります。
機種によってファストパスの実装方法が異なりますので、それぞれについて説明します。
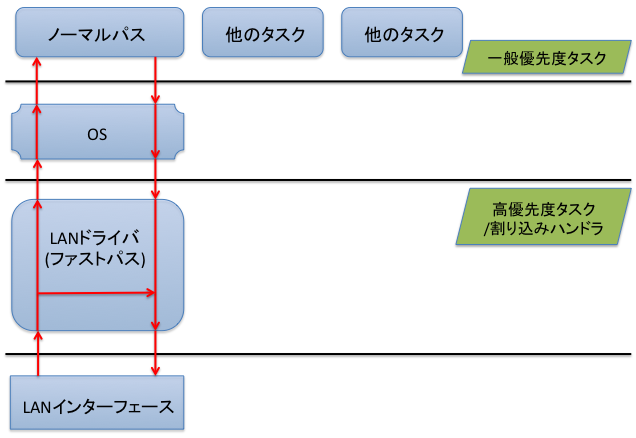
ファストパスをソフトウェアで実装している機種では、ファストパス、ノーマルパスとも一つのCPUでパケット転送処理を行います。CPUに特別な機能を搭載しているわけではなく、ファストパスとノーマルパスの処理の優先度を変えることで高速転送を可能にしています。
ノーマルパスによる処理の場合は、LANインターフェースから受信したパケットを、いったんLANドライバソフトが受信した後にOSを通じてノーマルパスを処理するソフトに引き渡すのに対して、ファストパスではLANドライバソフト内で処理をすべて終えてしまいます。LANドライバソフトは割り込みハンドラまたは高優先度タスクとして動作しているのでパケットを受信したら最優先で処理されるのに対し、ノーマルパスはその他のタスクと同様の一般優先度による処理なので、パケットを処理中でもタスクスイッチや割り込みの発生によって処理が遅れることがあります。
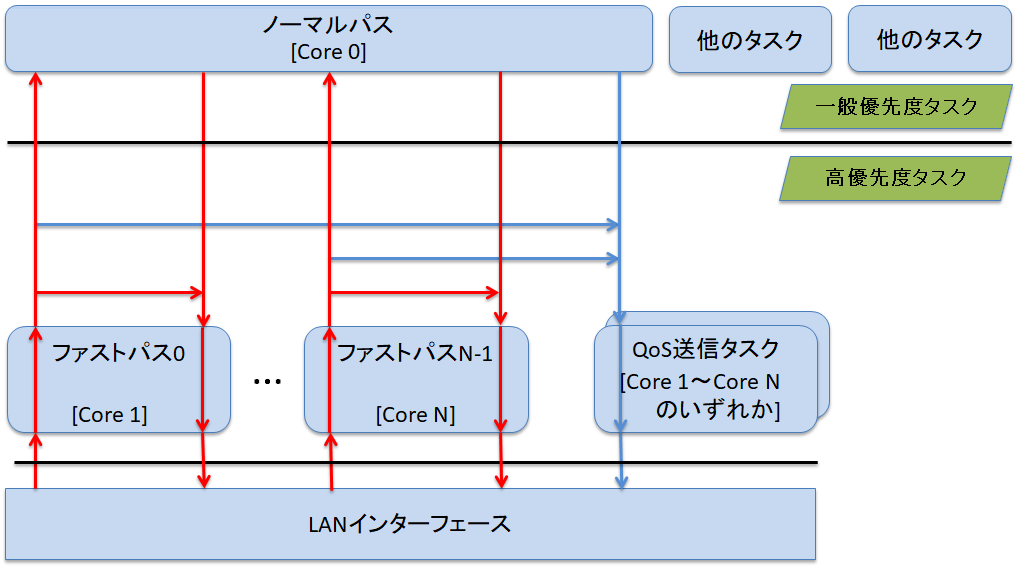
vRXシリーズはソフトウェアルーターです。仮想CPUコア数はデプロイ時の設定により決まります(機種ごとに動作保証対象のコア数が定められています)。ノーマルパスはコア0でパケット転送処理を行い、ファストパスはコア1以降のコアでパケット転送処理を行います。
コア数が3以上の場合、受信パケットをどのコアに振り分けるかをLANインターフェースが決定します。各コアで動作しているLANドライバソフトがパケットをLANインターフェースから受け取ると、シングルコア機種と同様のファストパス処理を行います。
コアの振り分けは、CPUスケジューリング(パケット転送)機能の設定に従って決定されます。
vRXシリーズのCPUスケジューリング(パケット転送)機能については、以下の文章を参照してください。
QoSを有効化している場合や、基本ライセンスの投入または非投入による送信帯域制限が10Gbps未満の場合、およびvRXさくらのクラウド版では、下の図中の青線で示すように、パケットはファストパスタスクやノーマルパスタスクからQoS送信タスクに引き渡されます。(vRX Amazon EC2版を除く)
QoS送信タスクはLANインターフェースごとに用意されており、ファストパスタスクやノーマルパスタスクは、転送先のLANインターフェースに紐づけられたQoS送信タスクにパケットを引き渡します。
QoS送信タスクは、各コアの負荷が分散されるように、ファストパスタスクの負荷状況に応じて、コア1以降の適切なコアで動作します。
RTX5000/RTX3500はマルチコアCPUを搭載しています。コア数は4で、すべてのコアにおいてLANドライバソフトが高優先度タスクとして動作しています。
ルーターがパケットを受信すると、LANインターフェースがそのパケットをどのコアに振り分けるかを決定します。各コアで動作しているLANドライバソフトがパケットをLANインターフェースから受け取ると、シングルコア機種と同様のファストパス処理を行います。
コアの振り分けは、CPUスケジューリング(パケット転送)機能の設定に従って決定されます。
RTX5000/RTX3500のCPUスケジューリング(パケット転送)機能については、以下の文章を参照してください。
ノーマルパスタスクはコア1で動作しています。
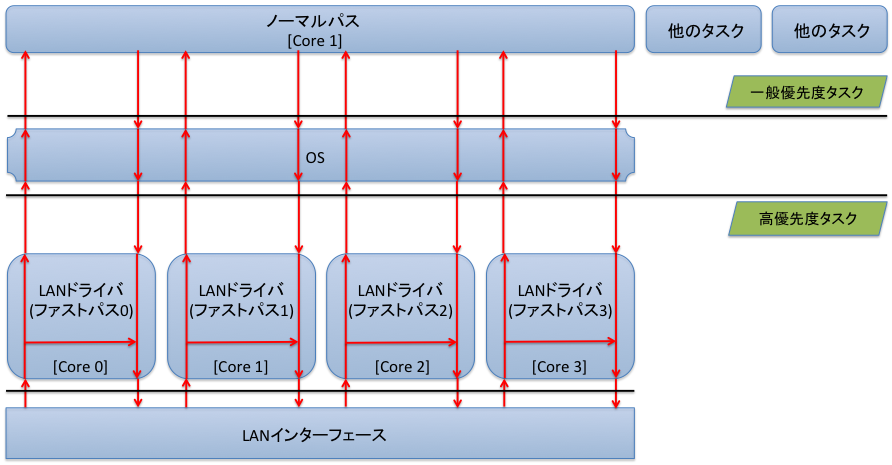
4個のコアで同時にファストパス処理が実行される場合に最大のスループットが得られます。1個のコアのみでファストパス処理が実行される場合のスループットは最大スループットの約1/4になります。
RTX1500は、CPUとしてADI AD6846を利用しています。このAD6846はメインCPUとしてMIPS系RISC CPUを1個、パケット転送や暗号化処理などを行うための専用のアクセラレータプロセッサと呼ばれるサブCPUを5個搭載しています。5個あるアクセラレータプロセッサの内訳は、3つあるLANインターフェースにそれぞれ1つずつ、暗号化専用に1つ、バッファ管理などの汎用の目的に1つとなります。RTX1500のファストパスでは、メインCPUを使わず、アクセラレータプロセッサだけでパケットを転送します。
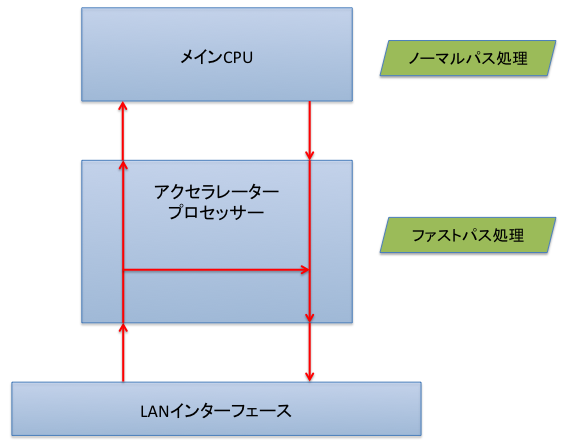
アクセラレータプロセッサはパケット処理専用に設計されたCPUであり、通常のCPUのような複雑な処理を行うことはできません。その代わりに高速にパケット処理ができるようにさまざまな工夫が施されています。また、それぞれのアクセラレータプロセッサは並列に動作できるため、複数のLANインターフェースからの入力を同時に扱ってもスピードが落ちることがありません。
RTX2000は、CPUとしてIntel IXP1200を利用しています。このIXP1200はメインCPUとしてStrongARMを1個、パケット転送専用のマイクロエンジンと呼ばれるサブCPUを6個搭載しています。RTX2000のファストパスでは、メインCPUを使わず、マイクロエンジンだけでパケットを転送します。
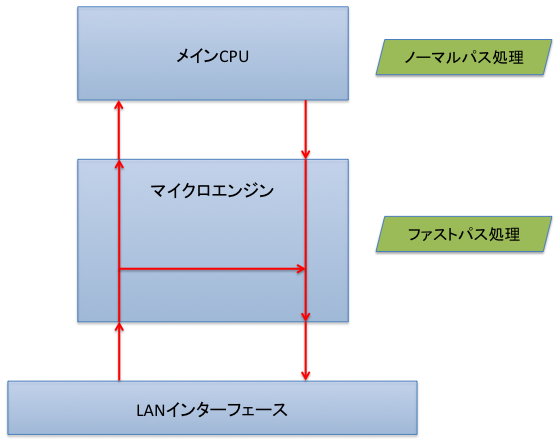
マイクロエンジンはパケット処理専用に設計されたCPUであり、通常のCPUのような複雑な処理を行うことはできません。その代わりに高速にパケット処理ができるようにさまざまな工夫が施されています。また、6個あるマイクロエンジンは個々が並列に動作できるのみならず、1個あたり最大4つのスレッドをハードウェア的に切替えながら同時に走らせることができます。そのため、多くのLANインターフェースからの入力を同時に扱ってもスピードが落ちることがありません。
以下のコマンドで、ファストパスを動作させるかどうかを選択できます。
以下のような条件に該当するパケットは必ずノーマルパスで処理されます。
IPv4およびIPv6の静的/動的フィルタ、IPv4のNAT/IPマスカレードの処理では、TCPとUDPだけがファストパスで処理されます。ただし、フローの先頭のパケットだけはフィルタの適用結果やNATの変換方法をファストパス用のキャッシュであるフローテーブルに記録する必要があるため、ノーマルパスでの処理となります。同じフローの後続のパケットはフローテーブルを利用しながらファストパスで処理します。
IPsecによるVPNにおいて、機種ごとに以下の種類のトンネルをファストパスで処理でします。
注: RT57i、RT58i、NVR500、NVR510はIPsecの機能を持っていません。
| 機種 | IPv4 over IPv4 | IPv6 over IPv6 | IPv4 over IPv6 | IPv6 over IPv4 |
|---|---|---|---|---|
| RTX2000 | ○ | × | × | × |
| RTX1500 | ○ | × | × | × |
| vRXシリーズ | ○ | ○ | ○ | ○ |
| RTX5000 | ○ | ○ | ○ | ○ |
| RTX3510 | ○ | ○ | ○ | ○ |
| RTX3500 | ○ | ○ | ○ | ○ |
| RTX1300 | ○ | ○ | ○ | ○ |
| RTX1220 | ○ | ○ | ○ | ○ |
| RTX1210 | ○ | ○ | ○ | ○ |
| RTX1200 | ○ | ○ | ○ | ○ |
| RTX1100 | ○ | ○ ※1 | ○ ※1 | ○ ※1 |
| RTX1000 | ○ | × | - | - |
| RTX840 | ○ | ○ | ○ | ○ |
| RTX830 | ○ | ○ | ○ | ○ |
| RTX810 | ○ | ○ | ○ | ○ |
| RT107e | ○ | ○ ※2 | ○ ※2 | ○ ※2 |
| FWX120 | ○ | ○ | ○ | ○ |
| SRT100 | ○ | ○ | ○ | ○ |
| NVR700W | ○ | ○ | ○ | ○ |
| RTV700 | ○ | × | - | - |
※1 Rev.8.03.42以降
※2 Rev.8.03.37以降
暗号アルゴリズム、認証アルゴリズムについてはハードウェア処理できるもののみファストパスで処理されます。ソフトウェア処理が必要なアルゴリズムを使う場合にはノーマルパスの処理となります。機種ごとに以下の通りです。
| 機種 | 暗号 | 認証 | |||||
|---|---|---|---|---|---|---|---|
| DES | 3DES | AES | AES256 | MD5 | SHA | SHA256 | |
| RTX2000 | ○ | ○ | × | × | ○ | ○ | × |
| RTX1500 | ○ | ○ | ○ | × | ○ | ○ | × |
| vRXシリーズ | ○ ※2 | ○ ※2 | ○ ※2 | ○ ※2 | ○ ※2 | ○ ※2 | ○ ※2 |
| RTX5000 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX3510 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX3500 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX1300 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX1220 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX1210 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX1200 | ○ | ○ | ○ | ○ ※1 | ○ | ○ | ○ ※1 |
| RTX1100 | ○ | ○ | ○ | × | ○ | ○ | × |
| RTX1000 | ○ | ○ | × | × | ○ | ○ | × |
| RTX840 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX830 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTX810 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RT107e | ○ | ○ | ○ | × | ○ | ○ | × |
| FWX120 | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| SRT100 | ○ | ○ | ○ | × | ○ | ○ | × |
| NVR700W | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| RTV700 | ○ | ○ | × | × | ○ | ○ | × |
○: ハードウェア処理できるアルゴリズム
×: ソフトウェア処理になるアルゴリズム
※1 Rev.10.01.32以降
※2 インテル AES-NIによる準ハードウェア処理
上記に加えて、ファストパスで処理するためには以下の条件を満たしている必要があります。
IP over IPトンネルにおいて、機種ごとに以下の種類のトンネルをファストパスで処理でします。
| 機種 | IPv4 over IPv4 | IPv6 over IPv6 | IPv4 over IPv6 | IPv6 over IPv4 |
|---|---|---|---|---|
| RTX2000 | × | × | × | × |
| RTX1500 | × | × | × | × |
| vRXシリーズ | ○ | ○ | ○ | ○ |
| RTX5000 | ○ | ○ | ○ | ○ |
| RTX3510 | ○ | ○ | ○ | ○ |
| RTX3500 | ○ | ○ | ○ | ○ |
| RTX1300 | ○ | ○ | ○ | ○ |
| RTX1220 | ○ | ○ | ○ | ○ |
| RTX1210 | ○ | ○ | ○ | ○ |
| RTX1200 | ○ | ○ | ○ | ○ |
| RTX1100 | ○※1 | ○※4 | ○※4 | ○※4 |
| RTX1000 | × | × | × | × |
| RTX840 | ○ | ○ | ○ | ○ |
| RTX830 | ○ | ○ | ○ | ○ |
| RTX810 | ○ | ○ | ○ | ○ |
| RT107e | ○ | ○※5 | ○※5 | ○※5 |
| FWX120 | ○ | ○ | ○ | ○ |
| SRT100 | ○ | ○ | ○ | ○ |
| NVR700W | ○ | ○ | ○ | ○ |
| NVR510 | ○ | ○ | ○ | ○ |
| NVR500 | ○ | ○ | ○ | ○ |
| RT58i | ○ | ○ | ○ | ○ |
| RT57i | ○※2 | × | × | × |
| RTV700 | ○※3 | × | × | × |
※1 Rev.8.03.24以降
※2 Rev.8.00.66以降
※3 Rev.8.00.69以降
※4 Rev.8.03.37以降
※5 Rev.8.03.42以降
IPsec、IPIPトンネルをファストパスで処理する条件は以下のようになります。
| コマンド設定 | IPv4 over IPv6 | IPv6 over IPv4 | IPv4 over IPv4 | IPv6 over IPv6 | |
|---|---|---|---|---|---|
| ip routing process | ipv6 routing process | ||||
| fast | fast | ◯ | ◯ | ◯ | ◯ |
| fast | normal | × | × | ◯ | × |
| normal | fast | × | × | × | ◯ |
| normal | normal | × | × | × | × |
◯: ファストパスで処理する
×: ノーマルパスで処理する
ファストパスではパケットの転送を高速に行うことを主眼としており、ノーマルパスでの処理を100%再現することはしていません。そのため、ノーマルパスに対して、以下のような機能の制限があります。
これはファストパスでパケットが処理された場合だけの制限ですから、パケットがノーマルパスで処理される場合にはこれらの機能は正しく働きます。例えば、pass-logフィルタを利用していると、最初の1パケットだけはフローテーブルを作るためにノーマルパスで処理されるためログに記録されるが、その後のパケットはファストパスで処理されるため記録されなくなるといった動作になります。
フローテーブルにはNAT/IPマスカレードでパケットがどのように変換されたかが記録されますが、パケットの入力側と出力側のインターフェースの両方でそれぞれNAT/IPマスカレードが適用されるような構成には対応していません。そのため、このような構成の場合にはファストパス機能を無効にする必要があります。
フローテーブルのサイズを越えたフローはノーマルパスで処理されるため、速度が落ちます。フローテーブルのサイズは有限で、各機種毎に以下の表のようになっています。これは片方向あたりですから、セッション数で言えばそれぞれ約半分となります。これを越える通信はノーマルパスでの処理となるので、ファストパスでの処理に比べて速度が大きく落ちてしまいます。特に、RTX2000では速度差が大きいので注意してください。
IPv6のファストパスに対応した機種、ファームウェアでは、IPv4、IPv6それぞれ別のフローテーブルで管理されます。
| 機種 | フローテーブルのサイズ |
|---|---|
| RTX2000 | Rev.7.01.29以前: 16,384 Rev.7.01.34以降: 65,536 |
| RTX1500 | 65,536 |
| vRXシリーズ | 最大 1,000,000 (※1) |
| RTX5000 | 131,072 |
| RTX3510 | 1,000,000 |
| RTX3500 | 131,072 |
| RTX1300 | 500,000 |
| RTX1220 | 131,072 |
| RTX1210 | |
| RTX1200 | 65,536 |
| RTX1100 | 16,384 |
| RTX1000 | |
| RTX840 | 300,000 |
| RTX830 | 131,072 |
| RTX810 | 32,768 |
| RT107e | 16,384 |
| FWX120 | 65,536 |
| SRT100 | 16,384 |
| NVR700W | 131,072 |
| NVR510 | |
| NVR500 | 16,384 |
| RT58i | |
| RT57i | |
| RTV700 |
※1 ip flow limitコマンド設定値に従う
| 機種 | 優先制御 /帯域制御 |
IPsec ESP トンネルのUDP カプセリング |
TOS フィールド の書き換え |
DS フィールド の書き換え |
reject フィルタ のログ |
ESPパケット のフィルタ リング |
IDS |
|---|---|---|---|---|---|---|---|
| RTX2000 | ○ | ○ | × | × | × | × | × |
| RTX1500 | ○ | × | ○※2 | × | ○ | ○ | × |
| vRX Amazon EC2版 vRX VMware ESXi版 |
○ | ○ | ○ | × | ○ | × | ○ |
| vRX さくらのクラウド版 | ○ | ○ | ○ | ○ | ○ | × | ○ |
| RTX5000 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX3510 | ○ | ○ | ○ | ○ | ○ | × | ○ |
| RTX3500 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX1300 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX1220 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX1210 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX1200 | ○ | ○ | ○ | × | ○ | × | ○ |
| RTX1100 | ○ | ○ | ○※2 | × | ○ | × | × |
| RTX1000 | × | ○ | × | × | ○ | × | × |
| RTX840 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX830 | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| RTX810 | ○ | ○ | ○ | × | ○ | × | ○ |
| RT107e | ○※1 | ○ | × | × | ○ | × | × |
| FWX120 | ○ | ○ | ○ | × | ○ | × | ○ |
| SRT100 | ○ | ○ | ○ | × | ○ | × | ○ |
| NVR700W | ○ | ○ | ○ | ○※3 | ○ | × | ○ |
| NVR510 | ○ | - | × | × | ○ | × | ○ |
| NVR500 | × | - | × | × | ○ | × | ○ |
| RT58i | × | - | × | × | ○ | × | × |
| RT57i | × | - | × | × | ○ | × | × |
| RTV700 | × | ○ | × | × | ○ | × | - |
※1 Rev.8.03.90以降
※2 Rev.8.03.24以降
※3 Rev.23.00.05以降、Rev.15.04.05以降、Rev.15.02.27以降、Rev.15.00.24以降、Rev.14.01.42以降、Rev.14.00.34以降
ファストパスで対応する場合は○、そうでない場合は×、その機能がない場合は−で示します。
ソフトウェア実装の機種およびRTX1500では、rejectフィルタによりパケットを落すと決めたフローのパケットはノーマルパスに回すようになっていますが、RTX2000ではrejectフィルタによりパケットを落すと決めたフローのパケットはマイクロエンジン内で破棄してしまい、メインCPUにまで通知しません。そのため、ログも記録できなくなっています。
またソフトウェア実装の機種およびRTX2000では、ESPパケットはフィルタリングの処理対象外です。
IPIPトンネリングおよびmap-eトンネル環境下において、カプセル化された受信パケットはフィルタリングの処理対象外です。
ファストパスで処理する場合は○、そうでない場合は×、その機能がない場合は−で示します。
| 機種 | LAN分割機能の ポートを経由 するパケット |
VRRP使用時の 通過パケット |
終点IPアドレスが マルチキャスト アドレスの パケット |
プライマリと セカンダリ間など の同一LANインター フェース間の 通信パケット |
折り返しパケット |
|---|---|---|---|---|---|
| RTX2000 | - | ○ | × | × | ○ |
| RTX1500 | × | ○ | ○※1 | ○ | ×※2 |
| vRXシリーズ | - | ○※3 | × | × | ○ |
| RTX5000 | ○ | ○ | × | × | ○ |
| RTX3510 | ○ | ○ | × | × | ○ |
| RTX3500 | ○ | ○ | × | × | ○ |
| RTX1300 | ○ | ○ | × | × | ○ |
| RTX1220 | ○ | ○ | × | × | ○ |
| RTX1210 | ○ | ○ | × | × | ○ |
| RTX1200 | ○ | ○ | × | × | ○ |
| RTX1100 | × | ○※1 | × | × | ○ |
| RTX1000 | × | × | × | × | ○ |
| RTX840 | ○ | ○ | × | × | ○ |
| RTX830 | ○ | ○ | × | × | ○ |
| RTX810 | ○ | ○ | × | × | ○ |
| RT107e | × | ○ | × | × | ○ |
| FWX120 | ○ | ○ | × | × | ○ |
| SRT100 | × | ○ | × | × | ○ |
| NVR700W | ○ | ○ | × | × | ○ |
| NVR510 | - | - | × | × | ○ |
| NVR500 | - | - | × | × | ○ |
| RT58i | - | - | × | × | ○ |
| RT57i | - | - | × | × | ○ |
| RTV700 | - | - | × | × | ○ |
※1 Rev.8.03系以降
※2 Rev.8.03.92以降
※3 VRRP非機能機種を除く
ip routing process ip flow limit ipv6 routing process clear ipv6 neighbor cache lan type # コマンドのLAN分割設定を変更したとき vlan port mapping ip INTERFACE nat descriptor nat descriptor masquerade remove df-bit ip fragment remove df-bit ip tos supersede ip dscp supersede ipv6 dscp supersede lan backup leased backup pp backup tunnel backup ethernet filter ethernet INTERFACE filter ip filter ip filter set ip INTERFACE secure filter ipv6 filter ipv6 INTERFACE secure filter queue class filter queue INTERFACE class filter list ip inbound filter ipv6 inbound filter ip INTERFACE inbound filter list ipv6 INTERFACE inbound filter list ip policy filter ipv6 policy filter ip policy service ipv6 policy service ip policy interface group ipv6 policy interface group ip policy address group ipv6 policy address group ip policy service group ipv6 policy service group ip policy filter set ipv6 policy filter set ip policy filter set enable ipv6 policy filter set enable ip policy filter set switch ipv6 policy filter set switch system packet-scheduling system packet-scheduling filter system packet-scheduling filter list lbo use lbo list get go # リストの取得・更新に成功したとき